오픈미소스는 뭘 구현했나, ‘클로드 미소스’ 추정 구조를 파이토치로 뜯어보기
· tech
AI 타임스 기사로 국내에서도 눈에 띈 **오픈미소스(OpenMythos)**는 이름만 보면 마치 Anthropic 내부 모델이 유출되었거나 거의 그대로 복원된 것처럼 느껴진다. 그런데 공식 저장소를 직접 읽어보면 결이 조금 다르다.
이 프로젝트는 Anthropic의 실제 코드를 복원한 것이 아니라, 공개 논문과 공개된 추론을 바탕으로 “만약 Claude Mythos가 이런 방향이라면 어떤 구조일까?”를 PyTorch 코드로 묶어본 이론적 재구성에 가깝다.
그래서 이 글은 “클로드 미소스의 정답 공개”가 아니라, 왜 이런 조합이 지금 사람들을 흥미롭게 만드는지, 그리고 저장소에 실제로 어떤 구현이 들어 있는지를 이해하기 쉽게 정리하는 쪽에 초점을 맞췄다.
참고: 이 글에 들어간 일부 이미지는 공식 README와 코드 구조를 바탕으로 내가 다시 그린 설명 카드다. 공식 벤더 이미지가 아니라 이해를 돕기 위한 재구성 도식이라고 보면 된다.
먼저 결론만 보면
- 오픈미소스는 Anthropic 공식 구현이 아니다. 저장소 README에도
theoretical reconstruction이라고 분명히 적혀 있다. - 하지만 Looped Transformer + 안정화 기법 + MoE + MLA/GQA + ACT를 한 번에 묶어놔서, 차세대 reasoning 모델의 설계 방향을 보는 데는 꽤 흥미롭다.
- 특히 이 저장소는 “파라미터를 무조건 더 크게”보다 같은 블록을 더 오래, 더 안정적으로 반복하는 쪽에 무게를 둔다.

프로젝트 상태부터 짧게 체크
2026년 4월 24일 기준으로 내가 확인한 상태는 이렇다.
- GitHub 저장소:
kyegomez/OpenMythos - GitHub API 기준
created_at: 2026-04-18 - GitHub API 기준
pushed_at: 2026-04-22 - PyPI 패키지:
open-mythos - PyPI 최신 버전 확인값: 0.5.0
- PyPI 분류: Development Status :: 3 - Alpha
즉, 지금 단계의 오픈미소스는 “논문 아이디어를 적극적으로 코드로 엮는 빠른 실험 저장소” 쪽에 더 가깝다. 이미 제품으로 다듬어진 안정판이라기보다는, 가설을 담은 연구용 구현체로 읽는 편이 더 정확하다.
제일 먼저 선을 그어야 하는 부분
이 프로젝트를 흥미롭게 보는 것과 과장해서 읽는 것은 완전히 다른 얘기다.

정리하면 이렇다.
저장소에서 직접 확인되는 사실
- README는 이 프로젝트를 Anthropic과 무관한 독립적인 theoretical reconstruction이라고 명시한다.
open_mythos/main.py에는 실제로 Recurrent-Depth Transformer, MoE FFN, MLA/GQA attention, ACT halting, depth-wise LoRA, LTI 기반 안정화 injection이 구현돼 있다.training/3b_fine_web_edu.py에는 FineWeb-Edu 기반 학습 스크립트가 들어 있다.- PyPI 패키지로도 배포되고 있어 최소한 “문서용 코드”만은 아니다.
넘어가면 안 되는 해석
- 이걸 보고 Claude Mythos의 실제 내부 구조가 밝혀졌다고 말하면 안 된다.
- README에 적힌 “Mythos probably is …” 류의 설명은 저자 가설이지 Anthropic 확인본이 아니다.
1B~1Tvariant 표 역시 구성 프리셋으로 읽는 게 안전하다. 즉시 쓸 수 있는 공개 학습 완료 체크포인트라고 단정하면 위험하다.
내가 보기엔, 오픈미소스의 진짜 가치는 “정답 공개”가 아니라 지금 연구 커뮤니티가 어떤 조합을 미래형 reasoning 모델 후보로 보고 있는지를 한 번에 훑게 해준다는 데 있다.
구조는 생각보다 단순하다
README와 docs/open_mythos.md 기준으로 보면 OpenMythos의 뼈대는 크게 세 덩어리다.
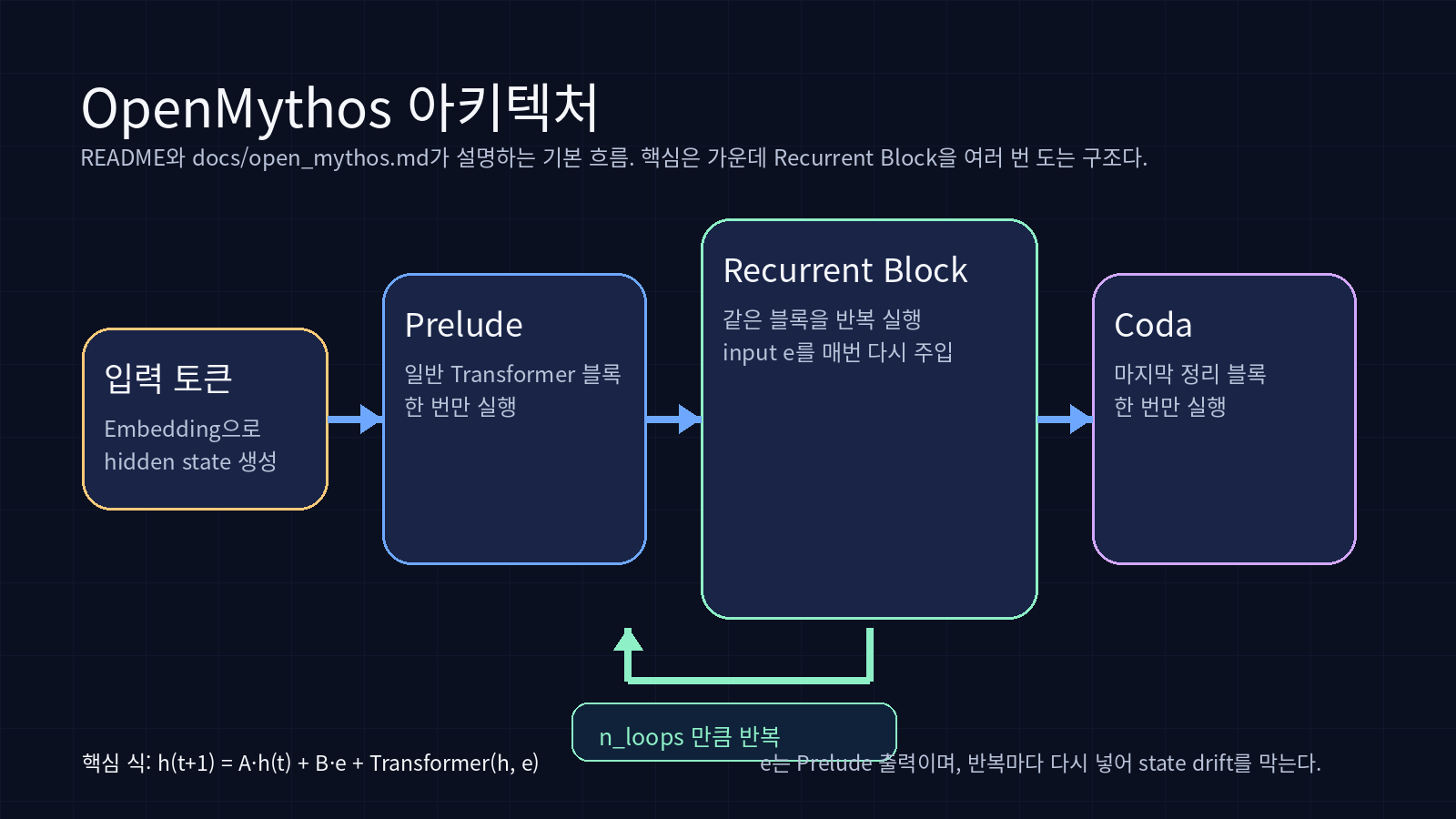
-
Prelude
- 일반 Transformer 블록을 몇 층 먼저 돌린다.
- 입력을 바로 반복 블록에 던지지 않고, 일단 “초기 인코딩”을 만든다.
-
Recurrent Block
- 여기서 같은 블록을
n_loops만큼 반복한다. - 이때 Prelude 출력
e를 매 반복마다 다시 주입한다.
- 여기서 같은 블록을
-
Coda
- 반복이 끝난 뒤 마지막 정리 블록을 한 번 더 거친다.
문서가 강조하는 업데이트 식은 대략 이렇다.
h(t+1) = A·h(t) + B·e + Transformer(h, e)여기서 중요한 건 e다. 입력에서 한 번 뽑아낸 정보를 반복마다 다시 넣어주기 때문에, loop가 길어져도 hidden state가 원래 입력에서 너무 멀어지는 것을 막겠다는 발상이다.
일반 Transformer와 가장 다른 점
보통 Transformer는 깊이를 늘릴 때 서로 다른 레이어를 더 쌓는 방식으로 간다. 반면 오픈미소스가 가정하는 구조는 같은 블록을 여러 번 도는 방식에 훨씬 가깝다.

이 차이가 왜 중요하냐면, 모델을 키우는 기준이 달라지기 때문이다.
- 일반 Transformer: 깊이를 늘리면 파라미터도 같이 늘어남
- Looped Transformer: 깊이를 늘려도 파라미터는 거의 그대로, compute만 증가
이 구조가 매력적인 이유는 분명하다. 같은 모델이라도 쉬운 문제에는 적게 돌리고, 어려운 문제에는 더 많이 돌리는 식으로 test-time compute scaling을 걸 수 있기 때문이다.
반대로 어려운 점도 뚜렷하다. 같은 블록을 계속 돌리면 학습이 불안정해지기 쉽고, 너무 많이 돌리면 오히려 overthinking 쪽으로 흐를 수 있다. 그래서 오픈미소스는 단순 loop가 아니라, 그 위에 여러 안전장치를 얹는다.
Recurrent Block 안에 들어간 진짜 핵심들

docs/open_mythos.md와 open_mythos/main.py를 같이 읽어보면, 반복 블록에는 다음 요소들이 묶여 있다.
1) Loop index embedding
같은 블록을 반복하면 “지금이 1회차인지 8회차인지”를 모델이 구분하기 어려울 수 있다. 오픈미소스는 이를 위해 loop index embedding을 hidden state에 넣는다.
쉽게 말해, 같은 가중치를 쓰더라도 반복 횟수에 따라 초반엔 대략적인 구조 파악, 후반엔 세부 정제 같은 식의 역할 분화를 유도하려는 설계다.
2) LTI injection으로 안정성 확보
반복 구조는 멋있어 보이지만, 실제 학습에서는 hidden state가 폭주하기 쉽다. 오픈미소스는 이 문제를 LTI(선형 시간 불변) 계열 관점으로 다루며, A의 spectral radius가 1보다 작게 유지되도록 설계한다.
이 부분은 최근 논문 Parcae: Scaling Laws For Stable Looped Language Models의 아이디어를 강하게 반영한 것으로 보인다. 내 해석으로는, 오픈미소스가 그냥 “loop를 돈다”에서 그치지 않고 왜 안정적으로 돌 수 있어야 하는가까지 붙잡으려 한 지점이 바로 여기다.
3) ACT halting
모든 토큰이 항상 같은 loop 수를 가질 필요는 없다. 쉬운 위치는 빨리 멈추고, 어려운 위치는 더 오래 계산하게 만들면 효율이 좋아진다.
이 프로젝트는 ACT(Adaptive Computation Time) 방식의 halting 모듈을 넣어, 위치별로 누적 halting probability가 threshold를 넘으면 반복을 일찍 멈추는 구조를 쓴다.
즉, “반복형 모델은 무조건 느리다”가 아니라 필요한 데만 더 오래 계산한다는 쪽으로 설계가 가 있다.
4) MoE FFN
오픈미소스는 반복 블록의 FFN을 dense FFN 대신 Mixture-of-Experts로 바꿔 둔다. 구체적으로는,
- 일부 expert만 토큰별로 선택 활성화하고
- shared expert는 항상 켜두는 방식이다.
이 구조는 DeepSeekMoE 논문이 밀고 있는 방향과 닮아 있다. 즉, reasoning depth는 반복으로 만들고, 도메인 폭은 expert routing으로 넓히는 셈이다.
5) MLA 또는 GQA attention
attention도 하나로 고정하지 않았다. 설정에 따라
- GQA(Grouped Query Attention)
- MLA(Multi-head Latent Attention)
를 고를 수 있게 되어 있다.
여기서 특히 재미있는 건 MLA다. README와 문서는 MLA를 기본값으로 두고, KV cache를 압축해 메모리를 크게 줄이는 방향을 강조한다. 즉 이 프로젝트는 reasoning 구조뿐 아니라, 실제 추론 비용 쪽까지 같이 본다.
6) Depth-wise LoRA
오픈미소스는 완전한 weight tying만 고집하지 않는다. 대신 loop마다 작은 depth-wise LoRA 보정값을 얹어, 같은 블록이 반복될 때도 약간씩 다른 동작을 하게 만든다.
이건 “파라미터 절약”과 “표현력 확보” 사이 타협점처럼 보인다. 순수 재귀 구조보다 유연하고, 완전한 별도 레이어보다 가볍다.
저장소에서 직접 보면 어디부터 읽으면 좋은가
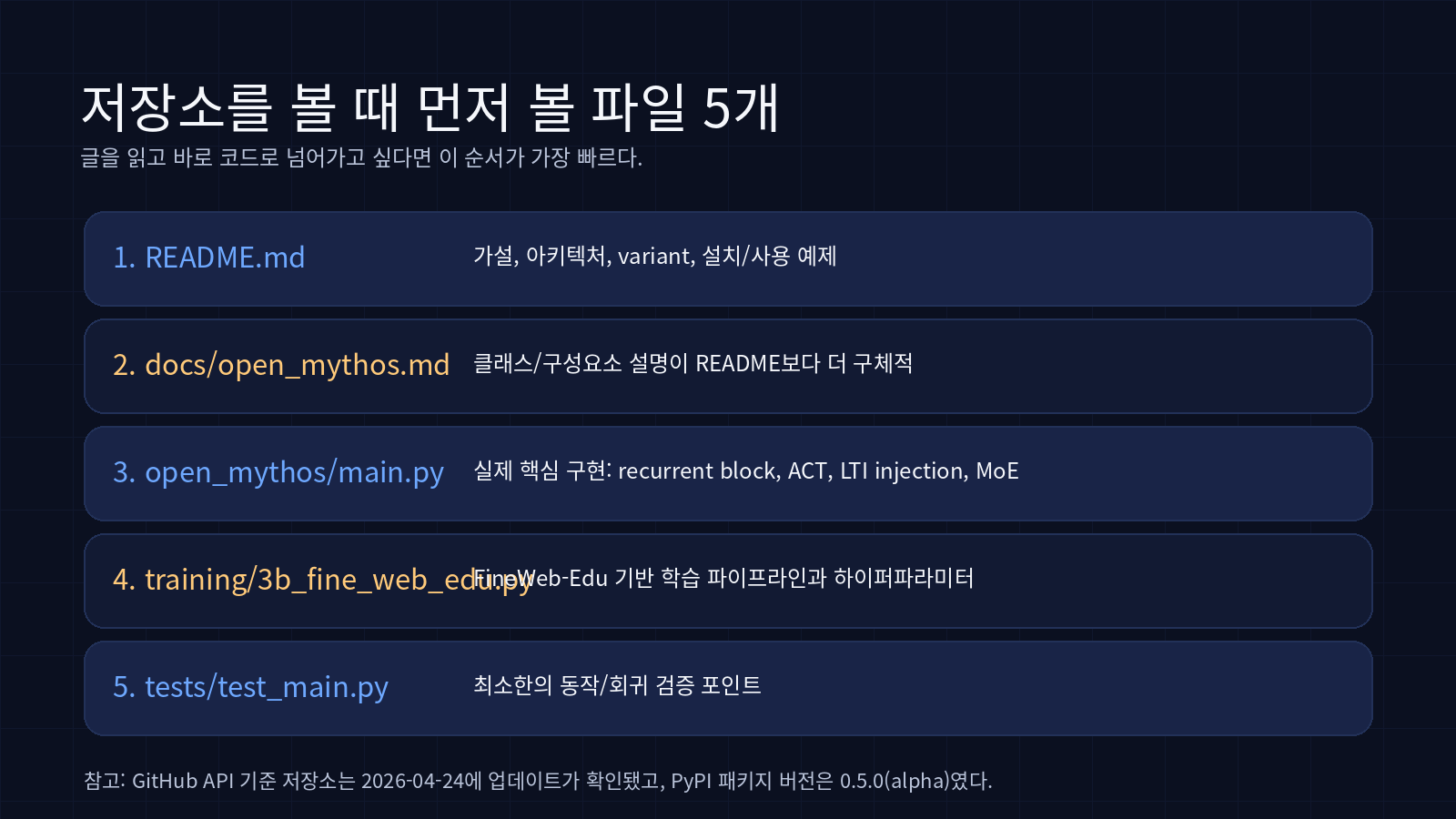
내 기준으로는 이 순서가 가장 효율적이었다.
README.md
전체 가설과 아키텍처 철학이 가장 압축돼 있다. 이 프로젝트가 무엇을 사실로 말하고, 무엇을 추정으로 말하는지 결이 여기서 드러난다.
docs/open_mythos.md
README보다 훨씬 실무적이다. MythosConfig, forward, generate, RecurrentBlock, LTIInjection, ACTHalting, LoRAAdapter가 어떤 역할을 맡는지 설명이 자세히 들어 있다.
open_mythos/main.py
실제 핵심 구현체다. 내가 보기엔 이 파일이 오픈미소스의 가치 대부분을 담고 있다. 단순한 장난감 예제라기보다, “이론을 실제 모듈 단위로 어떻게 분해했나”를 확인하는 파일에 가깝다.
training/3b_fine_web_edu.py
이 파일도 꽤 중요했다. 학습 스크립트 안에는 다음 정보가 들어 있다.
- 데이터셋:
HuggingFaceFW/fineweb-edu - 토크나이저:
openai/gpt-oss-20b - 최적화기: AdamW
- 병렬화: PyTorch DDP / FSDP
- 목표 토큰 수: 30B
- warmup 후 cosine decay 스케줄
즉, 오픈미소스는 단순히 “구조만 적어놓은 문서 repo”가 아니라, 적어도 학습까지 상정한 코드베이스다.
tests/
test_main.py, small_benchmark.py, bench_vs_transformer.py 같은 파일이 있다. 지금 상태를 production-grade라고 보긴 어렵지만, 적어도 이 프로젝트가 “README만 화려한 repo”에 머물지 않게 하려는 흔적은 보인다.
왜 연구적으로 이렇게 흥미로운가
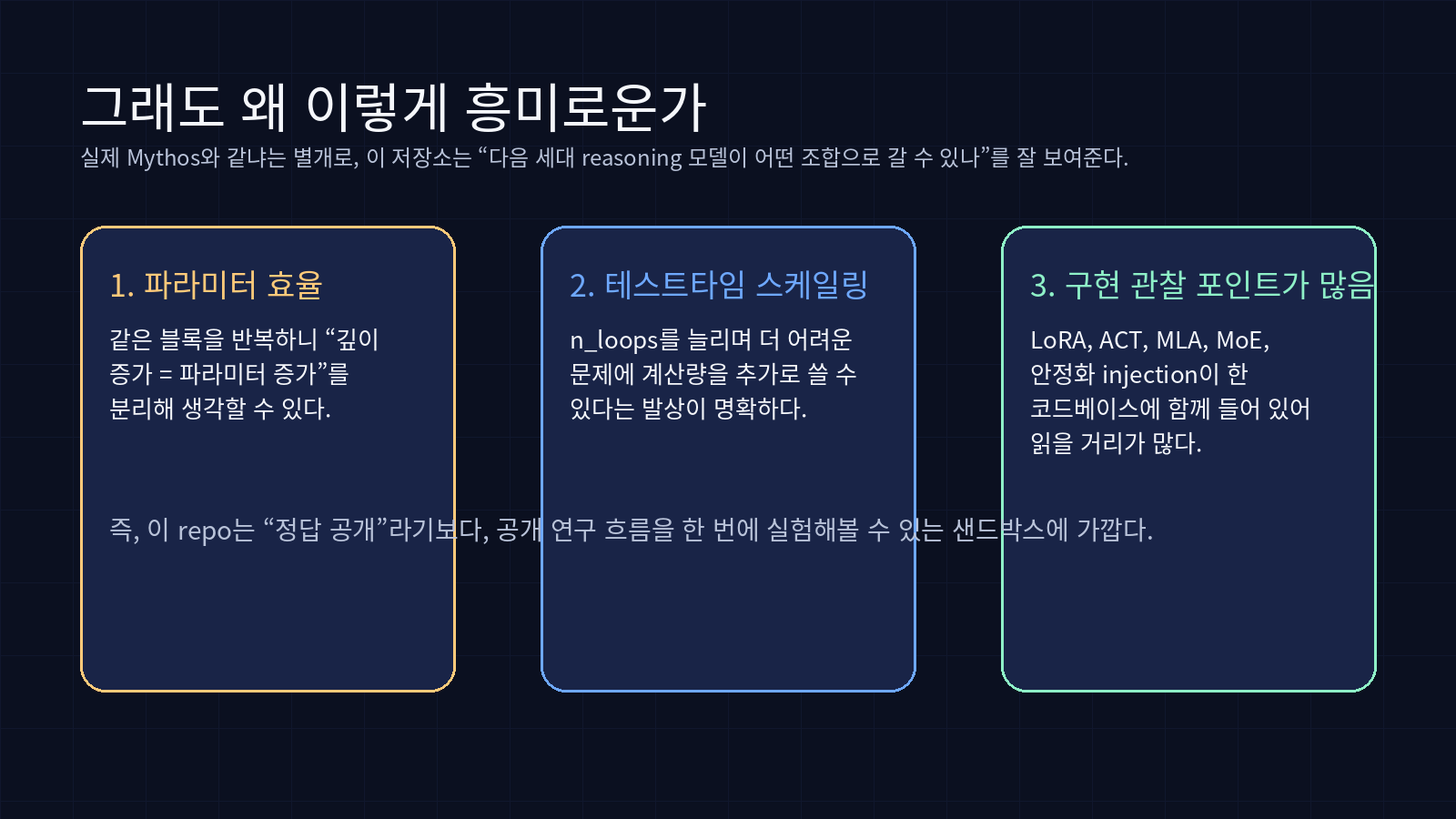
내가 이 프로젝트를 흥미롭게 본 이유는 세 가지다.
1) 파라미터와 추론 깊이를 분리해서 생각하게 만든다
보통 “더 잘하는 모델”을 떠올리면 파라미터를 먼저 떠올리기 쉽다. 그런데 오픈미소스가 채택한 사고방식은 조금 다르다.
- 저장되는 파라미터를 크게 늘리지 않고도
- 반복 횟수를 늘려 추론 깊이를 조절하고
- 필요한 토큰에만 더 많은 계산을 배정할 수 있다.
즉, reasoning 성능을 꼭 “더 큰 모델” 하나로만 설명하지 않아도 된다.
2) 여러 최신 아이디어가 한 코드베이스에서 만난다
오픈미소스는 아이디어 하나만 가져오지 않는다.
- stable loop training 쪽의 Parcae
- KV cache 효율화 쪽의 MLA / DeepSeek-V2
- sparse expert 쪽의 DeepSeekMoE
- halting 쪽의 Universal Transformer 계열 ACT
- parameter sharing 보완 쪽의 layer-wise LoRA / Relaxed Recursive Transformers
이게 왜 좋냐면, 논문은 보통 한 축만 깊게 파는데, 오픈미소스는 “이걸 다 합치면 어떤 형태가 되나”를 코드로 보여주기 때문이다.
3) 상용 reasoning 모델을 읽는 새로운 관점을 준다
Anthropic이 실제로 Mythos 내부를 이렇게 만들었는지는 아직 확인할 수 없다. 그래도 오픈미소스를 읽고 나면, 이후 나오는 reasoning 모델을 볼 때 시야가 달라진다.
예를 들어 예전에는 “모델이 왜 더 잘하지?”를 파라미터 수, 데이터 양, RL 정도로만 봤다면, 이제는 이런 질문이 생긴다.
- 이 모델은 내부적으로 같은 블록을 반복하나?
- test-time compute를 더 주면 성능이 오르나?
- depth-wise adaptation이나 halting이 들어 있나?
- KV cache를 줄이는 특수 attention을 쓰나?
이 질문들이 생긴다는 것 자체가 이미 꽤 큰 수확이다.
그렇다고 바로 믿으면 안 되는 이유
흥미롭다는 말과 검증됐다는 말은 다르다. 이 프로젝트를 볼 때는 특히 아래 세 가지를 같이 봐야 한다.
1) README가 매우 가설 중심이다
공식 문서 톤 자체가 “likely”, “suspected”, “probably” 류의 표현을 많이 쓴다. 즉, 이 repo는 애초에 가설을 밀어붙이는 탐색형 문서다.
2) variant 숫자는 설계 크기이지, 곧바로 검증된 제품 스펙이 아니다
README에는 1B부터 1T까지 variant 표가 나오지만, 그걸 그대로 “학습 완료된 공개 모델 목록”처럼 읽으면 안 된다. 내 해석으로는 이건 설계 스케일 프리셋에 더 가깝다.
3) 실제 Anthropic 모델과의 일치 여부는 아직 확인 불가다
결국 제일 중요한 것은 이것이다. 오픈미소스가 설득력 있는 연구 조합일 수는 있어도, 그게 곧 실제 Claude Mythos의 설계도라는 뜻은 아니다.
그래서 이 repo를 볼 때는 “진실 공개”보다 가능한 설계 공간을 좁혀주는 흥미로운 실험 정도로 받아들이는 편이 안전하다.
바로 만져보고 싶다면 여기서 시작하면 된다
설치와 최소 사용 예시는 README 기준으로 매우 직관적이다.
pip install open-mythos그리고 가장 간단한 사용 예시는 이런 식이다.
import torch
from open_mythos.main import OpenMythos, MythosConfig
cfg = MythosConfig(
vocab_size=1000,
dim=256,
n_heads=8,
max_seq_len=128,
max_loop_iters=4,
prelude_layers=1,
coda_layers=1,
n_experts=8,
n_shared_experts=1,
n_experts_per_tok=2,
expert_dim=64,
lora_rank=8,
attn_type="mla",
n_kv_heads=8,
kv_lora_rank=32,
q_lora_rank=64,
qk_rope_head_dim=16,
qk_nope_head_dim=16,
v_head_dim=16,
)
model = OpenMythos(cfg)
ids = torch.randint(0, cfg.vocab_size, (2, 16))
logits = model(ids, n_loops=4)
out = model.generate(ids, max_new_tokens=8, n_loops=8)이 예시만 봐도 오픈미소스가 어디에 방점을 찍는지 드러난다.
n_loops를 호출 단위로 바꿀 수 있고- attention 타입을
mla/gqa로 교체할 수 있고 - recurrent block에 MoE와 LoRA가 함께 붙어 있다.
즉, 단순한 “Transformer 한 번 구현해보기”가 아니라 연구 아이디어의 조합 실험장이라는 느낌이 강하다.
마무리
오픈미소스는 아직 검증 완료된 정답이라기보다, 지금 시점에 공개 연구를 바탕으로 가장 공격적으로 상상해볼 수 있는 reasoning 모델 설계 스케치에 가깝다.
그런데 오히려 그래서 더 재밌다. 상용 모델은 대개 내부가 닫혀 있어서 결과만 보게 되는데, 이런 저장소는 “왜 이런 구조를 떠올렸는지”를 문서와 코드로 같이 보여준다. 그리고 그 과정에서 앞으로의 LLM이 꼭 파라미터 숫자만으로 경쟁하지 않을 수도 있다는 힌트도 준다.
내 기준에서는, 이 프로젝트를 읽는 가장 좋은 태도는 두 가지를 같이 잡는 것이다.
- 과장하지 않기: Anthropic 공식 설계도로 착각하지 않기
- 가볍게 넘기지 않기: Looped Transformer와 test-time compute scaling이 실제로 중요한 축이 되고 있다는 신호로 보기
아마 다음에 reasoning 모델 관련 공개 자료가 더 나오면, 오픈미소스에서 제일 먼저 검증당할 것은 “반복 구조가 어디까지 핵심이었나”일 것이다. 그때 살아남는 가설이 무엇인지 보는 것도 꽤 재미있을 것 같다.
참고 링크
- AI 타임스 기사
- OpenMythos GitHub 저장소
- OpenMythos
docs/open_mythos.md - OpenMythos
training/3b_fine_web_edu.py - PyPI
open-mythos - Prairie et al., Scaling Laws For Stable Looped Language Models
- DeepSeek-AI et al., DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
- Dai et al., Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
- Ainslie et al., Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
- Bae et al., Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA
- Dehghani et al., Universal Transformers